Research Review: High Performance Monte-Carlo Based Option Pricing on FPGAs
- DSS Modeling

- Oct 28, 2025
- 7 min read
Background: The "Research Review" series is a grouping of articles that review scientific publications on the topics of financial modeling, foundation mathematics, and parallel computing. It is meant to enrich the community with technical knowledge and provide clarity on topics that can create distrust in the markets
Paper being review: Tian, Xiang, Khaled Benkrid and Xiaochen Gu. “High Performance Monte-Carlo Based Option Pricing on FPGAs.” Eng. Lett. 16 (2008): 434-442.
Introduction: The Convergence of High-Performance Computing and Modern Finance
The escalating computational complexity of modern financial models represents a significant challenge for the financial industry. As models for pricing derivatives and managing risk grow more sophisticated, often incorporating multiple stochastic variables, traditional computing methods struggle to deliver timely results. This creates a critical need for novel high-performance computing (HPC) solutions capable of handling these intensive workloads. The ability to perform complex simulations faster translates directly into a competitive advantage, enabling more accurate risk assessment and timely market decisions.
This paper argues that hybrid supercomputers, which combine conventional CPUs with Field-Programmable Gate Array (FPGA) accelerators, offer a compelling solution to this computational bottleneck. The Maxwell supercomputer, developed at the University of Edinburgh, exemplifies this architectural approach. By offloading the massively parallel components of financial simulations to a dedicated FPGA fabric, Maxwell achieves performance levels far exceeding those of traditional CPU-based clusters.
To demonstrate this capability, this paper details the implementation of a Monte-Carlo based Generalized Autoregressive Conditional Heteroskedastic (GARCH) option pricing model on the Maxwell platform. The key result is a performance speed-up of 340 times compared to an equivalent software implementation running on the system's own CPU cluster. This document will explore the computational demands of such models, provide a detailed overview of the Maxwell architecture, dissect the hardware implementation of the simulation engine, and analyze the performance results that validate this architectural strategy.
The Challenge: The Computational Demands of Stochastic Financial Models
Accurately pricing complex financial instruments is a cornerstone of modern finance, essential for trading, investment strategy, and risk management. For many advanced models, especially those involving three or more stochastic variables like fluctuating interest rates or volatility, closed-form analytical solutions are impractical or impossible to derive. This reality makes numerical methods, particularly Monte-Carlo simulations, the only viable alternative for obtaining a solution.
The Derivation of the Black-Scholes Model



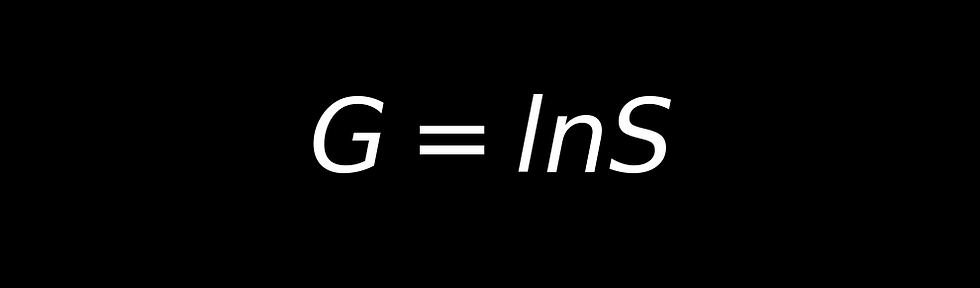

The Role of Monte-Carlo Simulations
Monte-Carlo simulation is a numerical technique that relies on repeated random sampling of model equations to compute their solutions. In finance, it is used to simulate the various sources of uncertainty—such as stock price movements and volatility changes—that affect the value of an instrument. The final price is determined by averaging the outcomes of thousands or even millions of independent, randomly generated paths. Because each simulated path is independent of the others, the entire workload is "embarrassingly parallel" and can be executed concurrently across many processing units, a characteristic that hardware accelerators are uniquely positioned to exploit.
Modeling Stochastic Volatility with GARCH
A key limitation of simpler models like Black-Scholes is the assumption of constant volatility. In reality, market volatility is itself a stochastic process. The Generalized Autoregressive Conditional Heteroskedastic (GARCH) model is a popular and powerful technique for modeling this non-constant, or stochastic, volatility. The most common variant, GARCH(1,1), defines volatility at a given time step based on the previous period's volatility and a random component.
The model equation is as follows:

Here, σᵢ is the volatility at time step i, while α, β, and σ₀ are constants derived from historical data. Critically, λ is an independent random variable drawn from a Gaussian distribution. The inclusion of this second, independent stochastic process—one for the stock price evolution (ε) and another for its volatility (λ)—doubles the demand for high-quality random numbers and fundamentally increases the computational workload per time-step, reinforcing the need for a hardware architecture designed to handle this compound parallelism.
The Maxwell Architecture: A Hybrid CPU-FPGA Supercomputing Platform
The Maxwell supercomputer is a purpose-built platform designed specifically to investigate the feasibility of running computationally demanding applications on a large array of FPGAs. Its hybrid architecture, which marries a traditional CPU cluster with a powerful FPGA accelerator fabric, is the key to its performance. This design allows tasks best suited for serial processing and system management to run on CPUs, while the massively parallel workloads defined in the previous section are offloaded to the FPGAs. The system is built on three core architectural pillars.
CPU Cluster Foundation
The conventional computing component of Maxwell consists of 32 blades, each containing a 2.8 GHz Xeon processor and 1 Gbyte of memory. This cluster provides the host environment for managing simulations, handling I/O, and executing the non-parallelizable portions of an application, serving as the control plane for the hardware accelerators.
FPGA Accelerator Fabric
Augmenting the CPU cluster is a fabric of 64 FPGAs distributed across the 32 blades. This reconfigurable hardware provides the logic for implementing custom, high-performance computing engines tailored to specific algorithms like Monte-Carlo simulation. The accelerator fabric consists of two types of cards: Nallatech H101-PCIXM cards, featuring Xilinx V4100LX devices, and AlphaData ADM-XRC-4FX cards, featuring Xilinx XV4FX100 devices. Each FPGA is also equipped with either 512 Mbytes or 1 Gbyte of private memory.
Multi-Layered Communication Infrastructure
A hybrid system's performance is ultimately governed by the efficiency of its communication infrastructure. Maxwell employs a three-tiered network to ensure efficient data flow between CPUs, FPGAs, and across the entire system, providing the necessary bandwidth for both control and high-performance data exchange.
This direct, high-bandwidth mesh is critical for future applications involving inter-path dependencies or more complex financial models, where the 'embarrassingly parallel' assumption begins to break down. This specialized architecture provides the robust foundation required to support the high-performance GARCH simulation engine detailed in the following section.
Hardware Implementation: The FPGA-based GARCH Simulation Engine
The theoretical benefits of the Maxwell architecture are realized through a bespoke hardware implementation of the Monte-Carlo simulation engine. The engine is architected for maximum parallelism and deep pipelining, ensuring that every available hardware resource is leveraged for performance.
A critical early design decision was the choice of arithmetic representation. To balance precision with resource efficiency, a detailed analysis was conducted in MATLAB, which determined that a 26-bit fixed-point wordlength was sufficient to meet the target precision requirement of 0.01%. For the final aggregation step, a wider 48-bit accumulator was used to prevent overflow. This fixed-point approach avoids the higher resource cost of floating-point units while delivering the necessary accuracy. The engine on each FPGA is composed of multiple parallel computing cores, each containing four key modules.
Box-Muller Gaussian Random Number Generator
To avoid the significant bottleneck of transferring random numbers from software, each Monte-Carlo core includes a dedicated hardware-based Gaussian random number generator. The implementation is based on the Box-Muller method, which uses two uniform random numbers to generate two statistically independent Gaussian samples. This is a perfect architectural fit for the GARCH model, which requires one random sample for the stock price evolution and a second, independent sample for the stochastic volatility process.
Pipelined GARCH Volatility Module
This module implements the GARCH equation to compute the everyday stochastic volatility. Although the GARCH equation contains a feedback loop where the current volatility depends on the previous one, the hardware architecture is carefully pipelined to ensure it can complete one full iteration per clock cycle. This high-throughput design is essential for maintaining the overall performance of the simulation engine.
Monte-Carlo Iteration Core
This core calculates the daily stock price evolution based on the GARCH volatility. A key optimization is the pre-calculation of constant expressions before they are fed into the core. The parameters q and w are computed within the GARCH module and then used by the iteration core, streamlining the main simulation loop.
This pre-calculation is a key hardware optimization, factoring out common terms to reduce the complexity and resource utilization of the main iteration core, which is instantiated multiple times on the FPGA.
Post-Processing and Aggregation
From a resource optimization perspective, the post-processing unit features a critical design choice. By mandating that the total number of paths is a power of 2, the division operation needed for averaging can be implemented with a simple and resource-efficient shift register instead of a large and complex divider unit. This architectural trade-off saves considerable resources, allowing more computing cores to be fitted onto a single FPGA and directly increasing the total parallelism and performance of the system.
This tightly integrated, highly optimized architecture translates directly into the real-world performance gains analyzed in the next section.
Performance Analysis and Results
The GARCH simulation engine was implemented and benchmarked on the AlphaData nodes of the Maxwell machine, which feature Xilinx XV4FX100 Virtex-4 devices. The performance was compared directly against an equivalent C++ software version running on Maxwell's 2.8 GHz Xeon processors. This section demonstrates how the architectural pillars of massive parallelism and bespoke pipelining, described in the third second, deliver the benchmarked performance.
The core implementation statistics highlight the density and efficiency of the hardware design:
Cores per FPGA: 11 independent Monte-Carlo cores were fitted onto a single Xilinx XV4FX100 FPGA.
Resource Utilization: The design occupied 39,466 slices (93.5% of the 42,176 available) and utilized all 160 available DSP48s units.
Clock Frequency: The design achieved a peak frequency of 53 MHz and was run conservatively at 50 MHz on the Maxwell hardware.
The primary performance result is a testament to the power of this architectural approach. The FPGA implementation achieved a 340-times speed-up over the equivalent software implementation running on the same number of nodes.
This remarkable gain was achieved despite the FPGA's relatively low clock frequency (50 MHz) compared to the CPU's high frequency (2.8 GHz). The source of this massive speed-up is twofold:
Massive Spatial Parallelism: While a 2.8 GHz CPU executes instructions serially on a handful of cores, each FPGA instantiates 11 complete, independent simulation engines, creating a spatially parallel architecture that processes 11 paths simultaneously.
Deep Temporal Pipelining: The bespoke hardware design achieves extreme temporal efficiency. Each of the 11 cores completes one full GARCH time-iteration every 20 ns clock cycle, a throughput impossible for a general-purpose CPU executing the same logic through a complex software stack. The performance gain comes not from a fast clock, but from a perfectly tailored, non-stop data-processing pipeline.
Comparative Benchmarking
When compared to previous work, this implementation demonstrates a substantial performance improvement. The work in [6] also implemented a GARCH model on a Virtex-4 FPGA, reporting a 49x speed-up. A demonstration application for a simpler Asian option model on Maxwell [7] reported a 323x speed-up. For a more direct comparison, this project's engine was also configured to price Asian options, achieving a 600x speed-up, substantially outperforming the prior Maxwell benchmark due to careful pipeline design and block mapping.

Conclusion and Future Work
This paper has demonstrated that the Maxwell supercomputer, through its hybrid CPU-FPGA architecture, provides an exceptionally effective platform for accelerating Monte-Carlo based financial simulations. By offloading the computationally intensive GARCH option pricing model to a custom-designed hardware engine, the system delivers performance far beyond the reach of conventional CPU-only clusters.
The main achievement is a fully parallelized and pipelined hardware engine that delivered a 340x performance increase over an equivalent software implementation. This result underscores the transformative potential of reconfigurable computing in finance. Furthermore, the project's success was enabled by the availability of a robust board support package and reusable IP cores, which allowed two first-year PhD students to complete the entire design, implementation, and testing in just five months. This rapid development cycle challenges the notion that hardware acceleration is prohibitively complex and time-consuming.



Comments